

Report: What can we learn from running qualitative analysis 108 times on an LLM?
A summary of findings from our 2025 AI + research workshops
Since ChatGPT’s debut in 2022, researchers and non-researchers alike have been attempting to adapt them as a rapid solution for qualitative analysis. Early evaluations of LLM effectiveness for this task have been informal and lacking in rigor, leaving questions about whether or not LLMs are up to the task. In this report, we introduce a more rigorous method for evaluating LLM analysis across multiple runs of the exact same prompt and dataset. In early 2025, we tested two of the most popular LLMs for research (GPT-4o and Claude 3.5 Sonnet), as well as gpt-oss-20b, and found that while they do produce plausible-looking themes, all three introduced serious errors, including quote fabrication and misattribution.
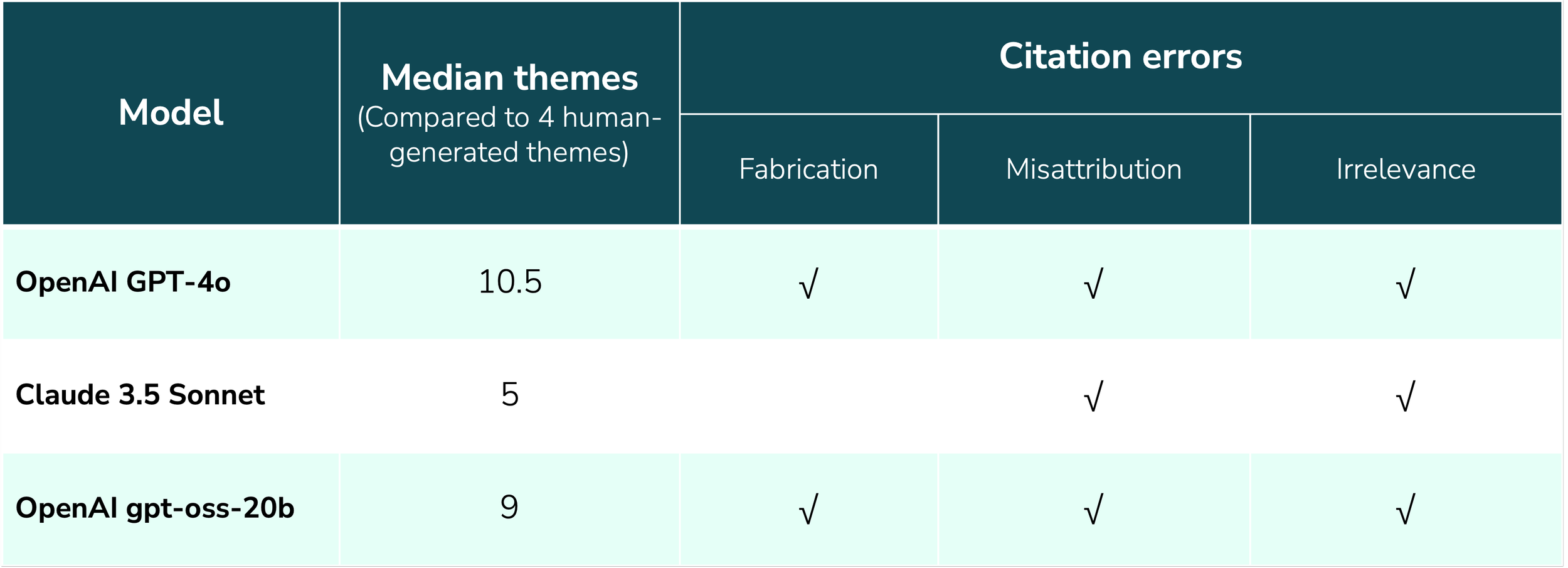
Summary of results observed with different models across our workshops
Read the original posts about the workshops
Request a copy of the report
I send out each report manually, so please allow up to a day for me to get you your copy!