

Report: What can we learn from running qualitative analysis 129 times on an LLM?
A summary of findings from our 2025 AI + research workshops
Executive Summary: Qualitative research analysis has emerged as a popular use case for large language models (LLMs). But as of late 2025 there were few (if any!) public, controlled evaluations of their accuracy and effectiveness for this task.
I’ve begun training researchers to do their own manual, controlled evaluations of LLMs for qualitative analysis. I’ve taught them to evaluate LLM-generated themes and supporting evidence (cited quotes) over multiple runs of the same prompt.
Over several workshops, participants took this approach to evaluate popular models used in current commercial research tools: GPT-4o (OpenAI), Claude 3.5 Sonnet (Anthropic), and Gemini 2.5 Flash (Google; used in NotebookLM), as well as locally run gpt-oss-20b (OpenAI).
While all four produced plausible-looking themes, they also introduced serious errors such as quote fabrication and misattribution. And because none of the LLMs consistently provided relevant supporting quotes, workshop participants felt it was ultimately “more work” to properly validate the analysis than to do it from scratch.
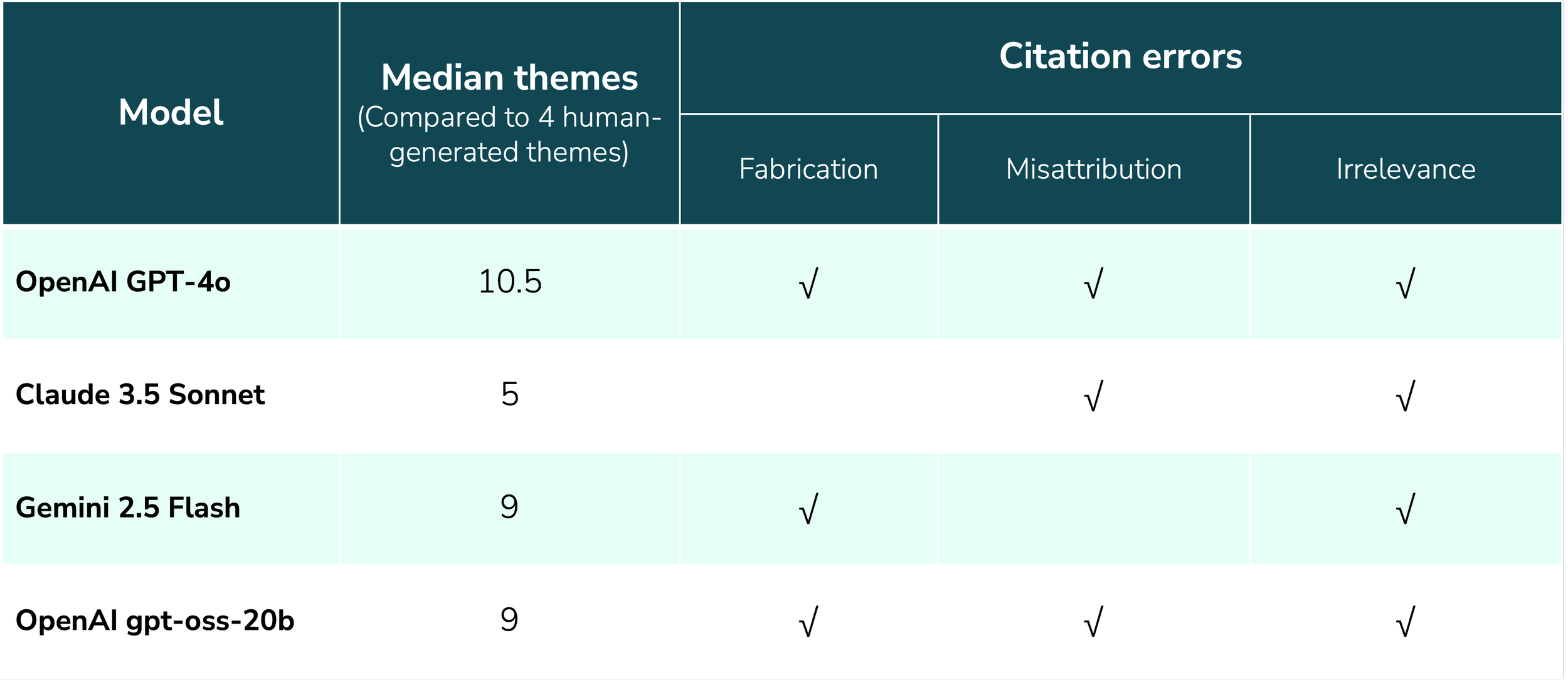
Summary of results observed with different models across our workshops
Read the original posts about the workshops
The full report includes the findings from the original posts above, plus a more comprehensive overview of the method and comparison of the results. It’s intended for user researchers and market researchers, UX professionals and managers, product managers, anyone else who conducts qualitative analysis on human data as part of their work.
Request a copy of the report
I send out each report manually, so please allow at least one business day for me to get back to you.